Nvidia lança IA que gera sons nunca ouvidos (com vídeo)
A Fugatto é capaz de produzir efeitos ou faixas sonoras completas, transformar a voz de uma pessoa, mudar-lhe o sotaque ou alterar a tonalidade para mais zangada ou mais calma, e até gerar sons irrealistas, como saxofones que miam e trompetes que ladram

Meios & Publicidade
Estão abertas as candidaturas ao ADCE Agency Exchange 2025


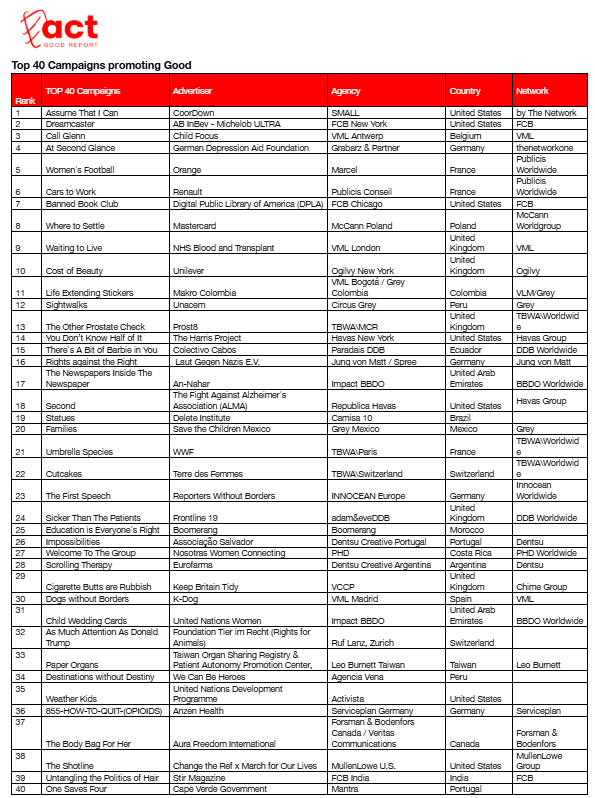
Há duas campanhas portuguesas no ACT Good Report 2025

Suíça é o primeiro país a exibir campanha global da Super Bock

Frize recorre a Ljubomir Stanisic para mudar paradigma

Kor Media ganha concessão de OOH nos autocarros de Évora e Beja

Emma Roberts é a primeira embaixadora global da Kiko Milano

O Lado B da edição 978 do M&P

Novobanco rejuvenesce marca com campanha da BBDO

Millie Bobby Brown e Jake Bongiovi promovem turismo do Dubai

P28 expõe arte em painéis publicitários de grande formato

A Fugatto (Foundational Generative Audio Transformer Opus 1), nova ferramenta de áudio da Nvidia, consegue gerar sons a partir de comandos de texto, criar excertos de música, remover ou adicionar instrumentos a uma canção existente e alterar o sotaque ou a emoção da voz, através de inteligência artificial (IA). De acordo com a Nvidia, que ainda não tem data prevista de disponibilização da Fugatto, esta é a primeira ferramenta capaz de produzir sons que nunca foram ouvidos.
O modelo é capaz de produzir efeitos ou faixas sonoras completas, transformar a voz de uma pessoa, mudar-lhe o sotaque ou alterar a tonalidade para mais zangada ou mais calma, através da apresentação de uma descrição em texto, o mais completa possível. Desta forma, a Fugatto é capaz de obter resultados fora do que é considerado real, como saxofones que miam e trompetes que ladram, por exemplo.
À semelhança de modelos como o ChatGPT, o Fugatto é também um modelo de IA generativa de larga escala. No entanto, em vez de ser treinado apenas com texto, o Fugatto é treinado com áudio. Em um documento técnico publicado pela Nvidia estão elencadas as fontes das bibliotecas de sons usadas para treinar o modelo, com cerca de 50 milhões de horas de conteúdo, incluindo um catálogo de efeitos sonoros da BBC, entre outros.